
This paper will be published in the proceedings of the Semantic Web Kick-off Seminar in Finland Nov 2, 2001 which is part of the Semantic Web in Finland effort
Marja-Riitta Koivunen and Eric Miller
{marja,emiller}@w3.org
W3C/MIT
The World Wide Web contains huge amounts of information created by many different organizations, communities and individuals for many different reasons. Users of the Web can easily access this information by specifying URI addresses, searching, and following links to find other related resources. The simplicity of usage is a key aspect that made Web so popular; so popular in fact, it is hard to imagine life without it anymore.
This simplicity of the current web has a price. It is very easy to get lost, or discover irrelevant or unrelated information with all that is available. For instance, if we search for something as simple as research papers written by a person named "Eric Miller" we will find all kinds of other information starting from Web diaries or phonebooks that mention "Eric" and/or "Miller" somewhere. Similar problems arise if you search for resources about "Marja" as "Marja" could equally well refer to a first name of a person, or to a berry in Finnish.
The goal of the Semantic Web is to develop enabling standards and technologies designed to help machines understand more information on the Web so that they can support richer discovery, data integration, navigation, and automation of tasks. With Semantic Web we not only receive more exact results when searching for information, but also know when we can integrate information from different sources, know what information to compare, and can provide all kinds of automated services in different domains from future home and digital libraries to electronic business and health services [Berners-Lee 2001].
With the Semantic Web we can associate semantically rich, descriptive information with any resource. For instance, by adding metadata about document creation, we can search for documents that have metadata specifying Eric Miller as a "writer". With a bit more metadata we can also search only documents under the category of "research papers". In Semantic Web we not only provide URIs for documents as we have done in the past, but to people, concepts and relationships. In the above case for example, by giving unique identifiers to the person, the role "writer" and the concept of "research paper" we make very clear who the person is, and the corresponding relation between this person and a particular document. Furthermore, by making clear which person we are talking about we can differentiate the plethora of "Eric Miller's". We can also combine descriptive information from different sites and learn more about this person in differing contexts; in his roles as an author, as a manager, as a developer, etc.
The Semantic Web provides the means to add specific information to the Web to aid in the automation of services, in the above case to discover and correlate, and the means of declaring the kind of information one might trust. An objective of the W3C Semantic Web activity is to standardize the key technologies that enable the non-centralized development while making sure that all the pieces fit together. In the following, we will first explain the main Semantic Web principles, then the key technological layers, and finally talk about the activity itself. In the end we will present a couple of sample Semantic Web applications.
People, places, and things in the physical world can be referred to in the Semantic Web by using a variety of identifiers. Anyone who has control over a part of Web namespace can create a URI and say that it identifies something in the physical world. Some people have insisted that only a small part of Web URI namespace is permissible for this purpose; e.g. those URIs starting with 'urn:'. The Semantic Web does not require, nor does it enforce, such restrictions. We can refer to physical entities also indirectly. For instance, we can refer to the person whose common name is "Marja-Riitta Koivunen" by using the URI to her e-mail inbox in a sentence such as: "The person whose email address is mailto:marja@w3.org and whose name is Marja-Riitta Koivunen.". We can then proceed to specify a great many more things about this person without ever having to assign another identifier to her. Similarly it is possible to identify a place, such as the city Helsinki, by referring to the URI of a page containing information about Helsinki maintained by the city offices. This is a pragmatic approach, with more metadata it is possible to describe the relation of the real city and the URI in more details.
The vocabularies we choose to use for describing resources are also defined by URIs. We may choose to Dublin Core's [DCMI 1999] unique identifer for 'author/creator' to express the relationship between the authors and this paper. The resources and their identifications presented in Figure 1 with some vocabulary for an event and a presentation could be used to explain, for instance, this presentation of the W3C Semantic Web activity during the Semantic Web kick-off event in Finland.
Figure 1: Resources from the physical world and their useful identifications in the Semantic Web.
The current Web consists of resources and links (see Figure 2). The resources are Web documents targeted for human consumption and do not commonly contain metadata explaining what they are used for and what are their relationships to other Web documents. While a knowledgeable human may realize easily that one resource is conceptually an invoice and another one is a novel or a research paper this information is often unavailable for a machine. Similarly a user can guess what kinds of relationships the resource has by reading the text around the link, but it is hard for the machine to make these same guesses. More informative relationships would be, for instance, "depends on", "is version of", "has subject", "authors".
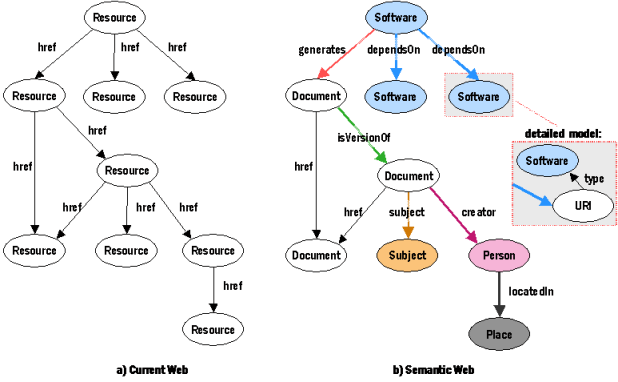
Figure 2: Resources and links can have types in the Semantic Web
As can be seen in Figure 2, also the Semantic Web consists of resources and links. However, now the resources and links can have types which define concepts that tell a bit more to the machines. For instance, some links may tell that a resource is a version of another resource or written by a resource that describes a person or that a resource contains software that depends on some other software. Here we have written the type inside the node to emphasize the similarities. The types are usually defined by a type link to a node with a URI address as illustrated in the detailed model in Figure 2.
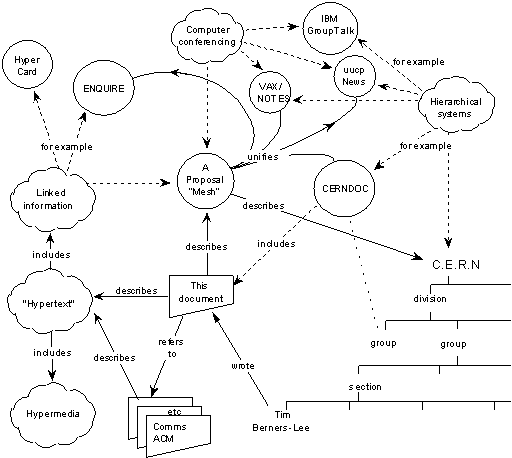
Figure 3: The Web as envisioned in 1989 by Tim Berners-Lee
Interestingly the different types for resources and links were already present in the original proposal for Web by Tim Berners-Lee as shown in Figure 3. He presented in this proposal that the Web of relationships amongst named objects can greatly unify and enhance the information management tasks [Berners-Lee 1989].
The current Web is unbounded: it sacrificed link integrity for scalability. Authors can easily link to other's resources as they don't have to worry about the links back to their resource. With no way to inform the linkers when the resources are moved we accept that we may get the 404 links presented in Figure 4 informing us that the link no longer leads to some Web resource.
Similarly the Semantic Web is unbounded: anyone can say anything about anything and create different types of links between resources. There will always be more to discover. Some of the linked resources may cease to exist or the addresses may be reused. The Semantic Web tools need to tolerate this data decay and be able to function in spite of that. For instance, we should be able to learn about Eric Miller's role in W3C Semantic Web Activity and use that information when making conclusions even if some other information linking to his other achievements is missing. Often the Semantic Web tools can work on selected information islands.
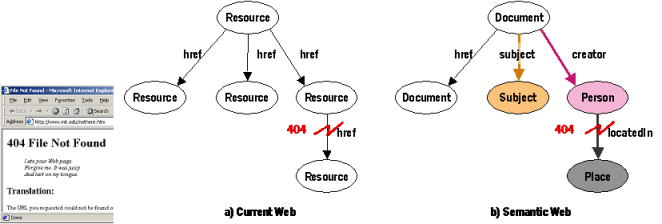
Figure 4: Both the current Web and the Semantic Web handle partial information
Not everything found from the Web is true and the Semantic Web does not change that in any way. Truth - or more pragmatically, trustworthiness - is evaluated by each application that processes the information on the Web. The applications decide what they trust by using the context of the statements; e.g. who said what and when and what credentials they had to say it.
In Figure 5 Tiina is an employee of Elisa who wants to visit W3C's member page. To do that she needs to give a proof that she has the rights to access the page. She does that by referring to the four statements made by Kari and Alan, who again are defined to have rights to give such statements, because of their roles as Elisa's Advisory Committee representative and W3C Associate Chairman respectively. The W3C application accepting the proof knows that it can trust Alan's statements and therefore also Kari's statements as Alan has delegated the responsibility for defining Elisa's list of employees with member access rights to Kari.
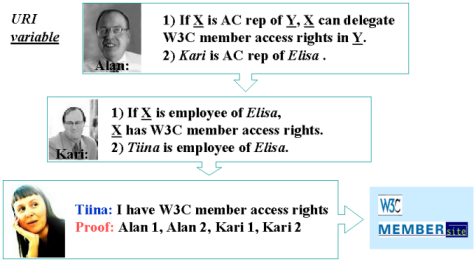
Figure 5: The chain of trust can define access rights.
It is common that similar concepts are often defined by different groups of people in different places or even by the same group at different times. It would often be beneficial to combine the data available on the Web that uses these concepts. The Semantic Web uses descriptive conventions that can expand as human understanding expands. In addition, the conventions allow effective combination of the independent work of diverse communities even when they use different vocabularies. The Semantic Web provides communities tools that can be used to resolve ambiguities and clarify inconsistencies. Also new information can be added without insisting that the old has to be modified.
In Figure 6 we present the current information of a person with last name Miller by using one vocabulary. At the same time some earlier information about the same person can be found in the Web. This information can be combined with the current information in many ways. We can add a new property "previousIdentity" that links the two persons together. We can also define a transformation from our current vocabulary to the vocabulary used by the earlier information e.g. to say that "worksAt" and "employedBy" define the same relation. It is also possible to add a new property defining a time period when the information was valid if the information does not already contain that. This additional information can be stored anywhere, where the relevant applications can find it, as it just refers to the URI of the earlier info. If the understanding of a property evolves over time, that too can be recorded by the Semantic Web facilities as properties can be first class objects with URIs.
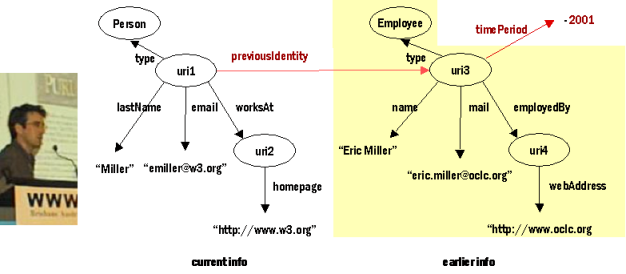
Figure 6: Combining new information with old when the old information cannot be changed.
The Semantic Web makes the simple things simple, and the complex things possible. The aim of the W3C activity is to standardize no more than is necessary. This approach enables the implementation of simple applications now that are based on already standardized technologies (e.g. Dublin Core [DCMI 1999], RSS [RSS 2000], MusicBrainz [MusicBrainz 2001]). At the same time there is research that plans for future complexity. When we use the Semantic Web technologies the result should offer much more possibilities than the sum of the parts.
The Semantic Web principles are implemented in the layers of Web technologies and standards. The layers are presented in Figure 7. The Unicode and URI layers make sure that we use international characters sets and provide means for identifying the objects in Semantic Web. The XML layer with namespace and schema definitions make sure we can integrate the Semantic Web definitions with the other XML based standards. With RDF [RDF] and RDFSchema [RDFS] it is possible to make statements about objects with URI's and define vocabularies that can be referred to by URI's. This is the layer where we can give types to resources and links. The Ontology layer supports the evolution of vocabularies as it can define relations between the different concepts. With the Digital Signature layer for detecting alterations to documents, these are the layers that are currently being standardized in W3C working groups.
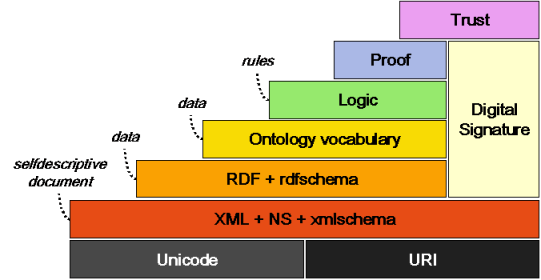
Figure 7: The Semantic Web layers
The top layers: Logic, Proof and Trust, are currently being researched and simple application demonstrations are being constructed. The Logic layer enables the writing of rules while the Proof layer executes the rules and evaluates together with the Trust layer mechanism for applications whether to trust the given proof or not.
The Semantic Web Activity is part of the W3C Technology and Society Domain. The aim of this activity is to design technologies that support machine facilitated global knowledge exchange. The main focus is information that can be consumed and understood by machines and means that make it cost-effective for people to record their knowledge. The focus of this work is on short term deployment while keeping an eye toward longer term research issues. With Semantic Web we can hopefully change the following situation familiar to many users.
"The bane of my existence is doing things that I know the computer
could do for me."
-- Dan Connolly, The XML Revolution
The Semantic Web Activity offers an environment for cooperation and collaboration. Currently it has two Working Groups that define enabling standards and technologies: The RDF Core Working Group [RDFCore] and The Web Ontology Working Group [WebOnt]. The Semantic Web Advanced Development projects explore prototype development in pre-competitive phase. These will be discussed more later. In addition, there are also public interest groups and other education and outreach activities that explain and clarify designs and goals, create implementation guidelines and try to understand policy implications.
The current Resource Description Framework (RDF) standard [RDF 1999] provides a common framework for representing metadata across many applications. The aim of RDFCore is to clarify and improve RDF's abstract model [Model 2001] and XML syntax according to feedback from implementors. This group is chartered to complete the RDF vocabulary description in the RDF Schema Candidate Recommendation[RDFS 2000]. The Working Group also explains the relationships between the basic components of RDF (Model, Syntax, Schema) and the larger XML family of recommendations.
The WebOnt working group standardizes means that can be used to define Web ontologies that describe structures of concepts. The DAML+OIL work supported by DARPA's DAML Initiative is given as input to this group. WebOnt builds on RDF Schema (classes and subclasses, properties and subproperties) while extending these constructs to allow a more complex relationships between entities. For instance, it can limit the properties of classes with respect to number and type. It also offers means to infer that items with various properties are members of a particular class and offers a well-defined model for property inheritance.
The SWAD projects explore prototype ideas in pre-competitive phase. It is a venue for liaison with research community and a testbed for early implementations of Working Drafts. It also offers a collaborative development environment for the Team and Members to explore ideas together. It stimulates the development of more Semantic Web infrastructure components. Some work has been done or is still done at least in the following areas:
"These ambiguities, redundancies, and deficiencies recall those
attributed by Dr. Franz Kuhn to a certain Chinese encyclopedia entitled
Celestial Emporium of Benevolent Knowledge. On those remote pages it is
written that animals are divided into (a) those that belong to the Emperor,
(b) embalmed ones, (c) those that are trained, (d) suckling pigs, (e)
mermaids, (f) fabulous ones, (g) stray dogs, (h) those that are included in
this classification, (i) those that tremble as if they were mad, (j)
innumerable ones, (k) those drawn with a very fine camel's hair brush, (l)
others, (m) those that have just broken a flower vase, (n) those that
resemble flies from a distance."
-- Essay: "The Analytical Language of John Wilkins", in La Nación, 8 February
1942
The story above defines a simple vocabulary classifying animals to classes in two hierarchical levels. Figure 8 presents this vocabulary as an RDF model. In the Semantic Web it is easy to define vocabularies in a formal way. In this example the "subClassOf" property is used for defining the class hierarchy.
Figure 8: RDF model of a simple vocabulary
In the Semantic Web it is easy to integrate information from several sources. The following example illustrates how easy it is to merge RDF based information.
DMOZ is an open directory project maintained by a large community of volunteers on the Web. Figure 9 presents the user interface of a DMOZ page that defines the category "Resource Description Framework - RDF". It will be referred simply as RDF category in the followingdiscussion. The first section of the page defines the category hierarchy starting from the "Top" parent class and ending with the RDF category. The subclasses of the RDF category itself, such as "Applications", "Standards Documents", and "Documentation", are presented in the next section of the page. The page also has a list of closely related categories under the "See also:" section.
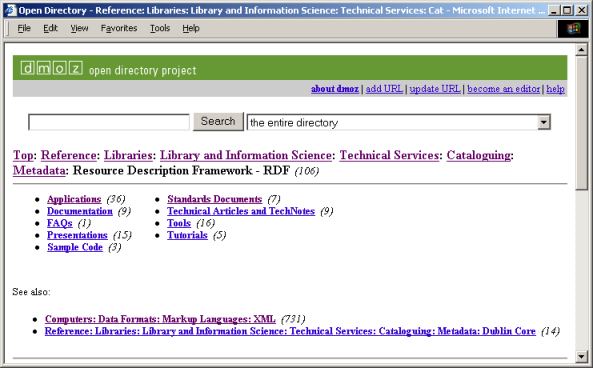
Figure 9: The DMOZ categories related to RDF category.
The RDF model of some of the categories in Figure 9 is presented in Figure 10. The "rdfs: subClassOf" relation defines the category hierarchy and the "rdfs:seeAlso" relation cites the related categories that are not directly part of this hierarchy.
Figure 10: RDF model of the DMOZ categories in Figure 9.
The DMOZ page also lists all the Web pages whose category is RDF (see Figure 11). The category for these pages is defined by using the "dc:subject" relation from the Dublin Core vocabulary [DCMI 1999]. It is easy to integrate this additional information into the RDF model presented earlier in Figure 10. Figure 12 presents the new RDF model with three sample pages belonging to RDF category.
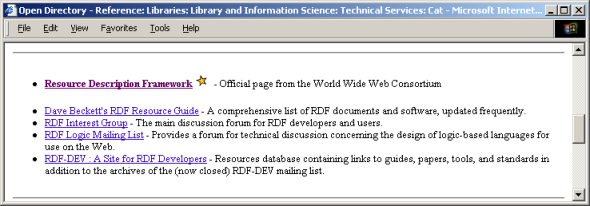
Figure 11: DMOZ pages with the RDF category.
Figure 12: Web pages with RDF category are integrated to the RDF model in Figure 10.
All the information presented so far is from the same source, the DMOZ directory. However, it is as easy to add information from other sources to the RDF data. For instance, we could use RDF to model the favorites hierarchy in the Web browser as illustrated in Figure 13. The model here uses a vocabulary defining a "bm:includes" relation for both subclasses and categories.
Figure 13: An RDF model for browser 'favorites'.
As the RDF category in both favorites and DMOZ RDF models has the same URI and therefore is the same concept, it becomes possible to merge the categories from the favorites directories into the information in the DMOZ directories as we have done in Figure 14. With ontologies it will be possible also to define the correspondence between the vocabularies in both models. If our client browser is capable of searching this information either from available Web servers and providing it in some form to the user, the user will be able to get not only the information he or she stored in the RDF category but also the information stored by the whole DMOZ open directory community. Naturally it is also possible to filter the information, for instance, only use the information created by some trusted contributors from the community. The RDF datastores can usually handle specialized queries; the clients just need to offer flexible interfaces for users to take full advantage of the possibilities.
Figure 14: Integrating the RDF model for favorites to the DMOZ model.
A lot of exiting things are happening right now in the W3C Semantic Web Activity. Working groups are established and technologies are standardized on the lower technological layers that are well understood. It is already possible to implement concrete applications based on this work. At the higher technological layers more research and consensus building is needed and information is gathered from experimental demonstrations.
In addition to the technologies, work is needed to develop tools and easy user interfaces that support users in understanding the metadata and adding the metadata into the Web. This support and automation will be critical in the deployment of the Semantic Web. When more and richer metadata appears there will be huge amounts of opportunities for various applications.
The W3C Semantic Web activity [SW] is based on the hard work of many contributors. Here we would like to thank Ralph Swick, Jose Kahan, and Dan Connolly for their many comments and help with this paper. Also special thanks to Elisa Communications for supporting Marja-Riitta Koivunen's work at MIT.
[Berners-Lee 1989] T. Berners-Lee.Information Management: A Proposal. CERN, March 1989, May 1990. http://www.w3.org/History/1989/proposal.html
[Berners-Lee 2001] T. Berners-Lee, J. Hendler, O. Lassila (2001), The Semantic Web, Scientific American, May 2001, pp. 28-37. http://www.scientificamerican.com/2001/0501issue/0501berners-lee.html
[DCMI 1999] Dublin Core Metadata Initiative, Dublin Core Metadata Element Set, Version 1.1, http://purl.org/dc/documents/rec-dces-19990702.
[Model 2001] P. Hayes (ed.). RDF Model Theory. W3C Working Draft, 25 September 2001. http://www.w3.org/TR/2001/WD-rdf-mt-20010925
[MusixBrainz 2001] MusicBrainz 2.0. http://www.musicbrainz.org/MM/
[RDF 1999] O. Lassila and R. R. Swick (eds.). Resource Description Framework (RDF) Model and Syntax Specification. W3C Recommendation, 22 February 1999. http://www.w3.org/TR/1999/REC-rdf-syntax-19990222.
[RDFCore] RDFCore Working Group. http://www.w3.org/2001/sw/RDFCore/
[RDFS 2000] D. Brickley, R.V. Guha (eds.). Resource Description Framework (RDF) Schema Specification 1.0. W3C Candidate Recommendation, 27 March 2000. http://www.w3.org/TR/2000/CR-rdf-schema-20000327.
[RSS 2000] RSS 1.0. http://groups.yahoo.com/group/rss-dev/files/specification.html
[SW] Semantic Web Development. http://www.w3.org/2000/01/sw/.
[WebOnt] Web-Ontology Working Group. http://www.w3.org/2001/sw/WebOnt/